ONE SENTENCE SUMMARY:
本文探讨了构建和改进推理模型的四种主要方法,强调了在快速发展的LLM领域中推理能力的重要性和应用。
MAIN POINTS:
- 推理模型通过中间步骤解决复杂任务,如数学和编程挑战。
- 深度学习模型的推理能力可以通过推理时间扩展和强化学习提高。
- 发展推理模型需要考虑成本和效率,尤其是在预算有限的情况下。
TAKEAWAYS:
- 推理模型适合复杂任务,但不适合简单问题。
- 通过模型蒸馏可以在有限预算下实现良好性能。
- 结合强化学习和监督微调是构建高性能推理模型的关键。
本文介绍了构建推理模型的四种主要方法,或如何增强大型语言模型(LLM)的推理能力。我希望这能为您提供有价值的见解,并帮助您在快速发展的文献和围绕这一主题的炒作中导航。
2024年,LLM领域出现了越来越多的专业化。除了预训练和微调之外,我们还见证了从RAGs到代码助手等专业应用的兴起。我预计这一趋势将在2025年加速,届时将更加重视领域和应用特定的优化(即“专业化”)。
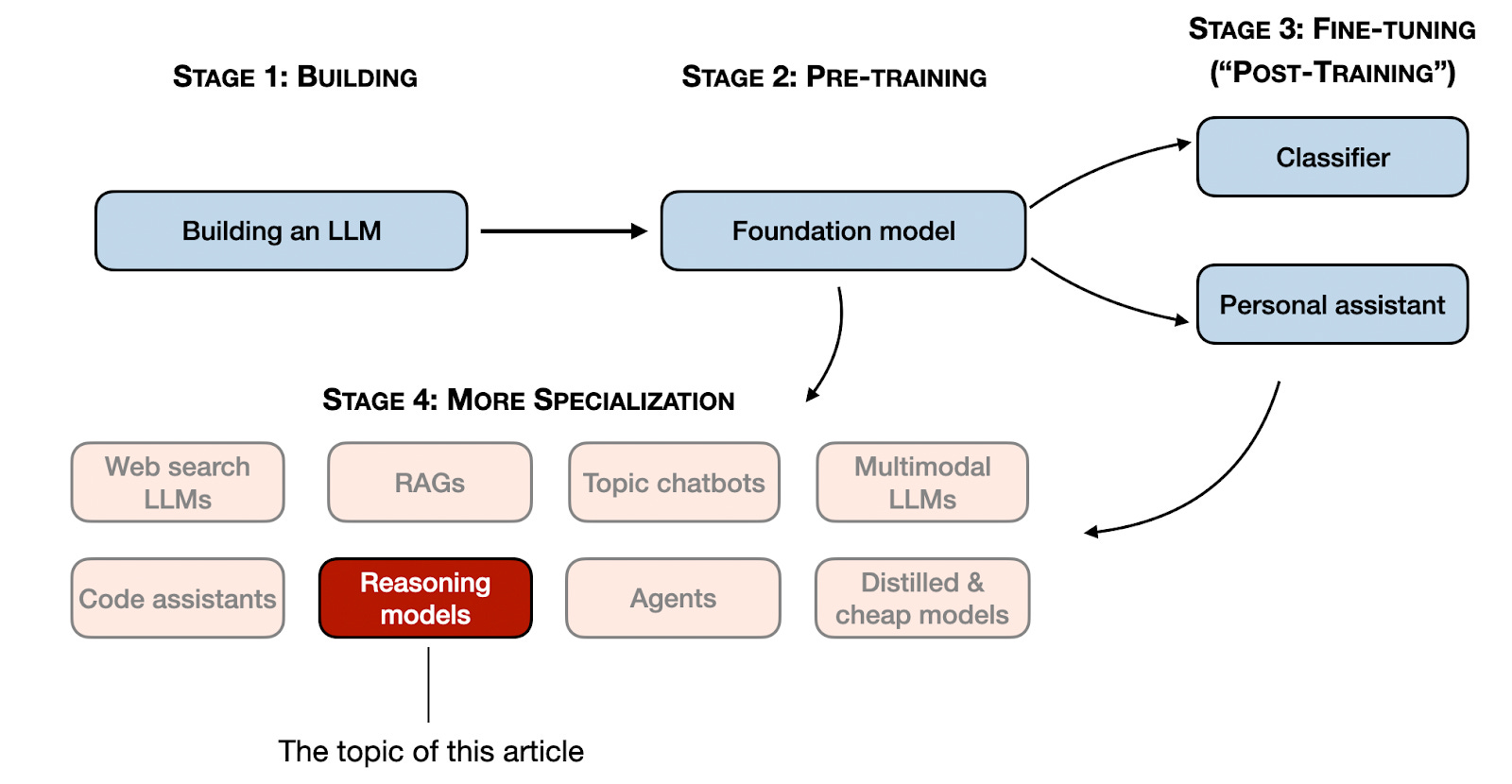
推理模型的开发是这些专业化之一。这意味着我们精炼LLM,使其在需要中间步骤的复杂任务中表现出色,例如谜题、高级数学和编程挑战。然而,这种专业化并不取代其他LLM应用。因为将LLM转变为推理模型也会引入某些缺点,我将在后面讨论。
为了让您对下面的内容有一个简要的了解,本文将:
-
解释“推理模型”的含义
-
讨论推理模型的优缺点
-
概述DeepSeek R1的背后方法
-
描述构建和改进推理模型的四种主要方法
-
分享对DeepSeek V3和R1发布后LLM格局的看法
-
提供在预算紧张的情况下开发推理模型的建议
我希望您在今年AI的快速发展中能发现这篇文章的实用性!
我们如何定义“推理模型”?
如果您从事AI(或一般的机器学习)工作,您可能对模糊且备受争议的定义并不陌生。“推理模型”这个术语也不例外。最终,会有人在论文中正式定义它,但在下一篇中又会被重新定义,依此类推。
在本文中,我将“推理”定义为回答需要复杂、多步骤生成且包含中间步骤的问题的过程。例如,像“法国的首都是哪里?”这样的事实性问答不涉及推理。相反,像“如果一列火车以60英里每小时的速度行驶3小时,它会走多远?”这样的问题则需要一些简单的推理。例如,它需要识别距离、速度和时间之间的关系,然后才能得出答案。
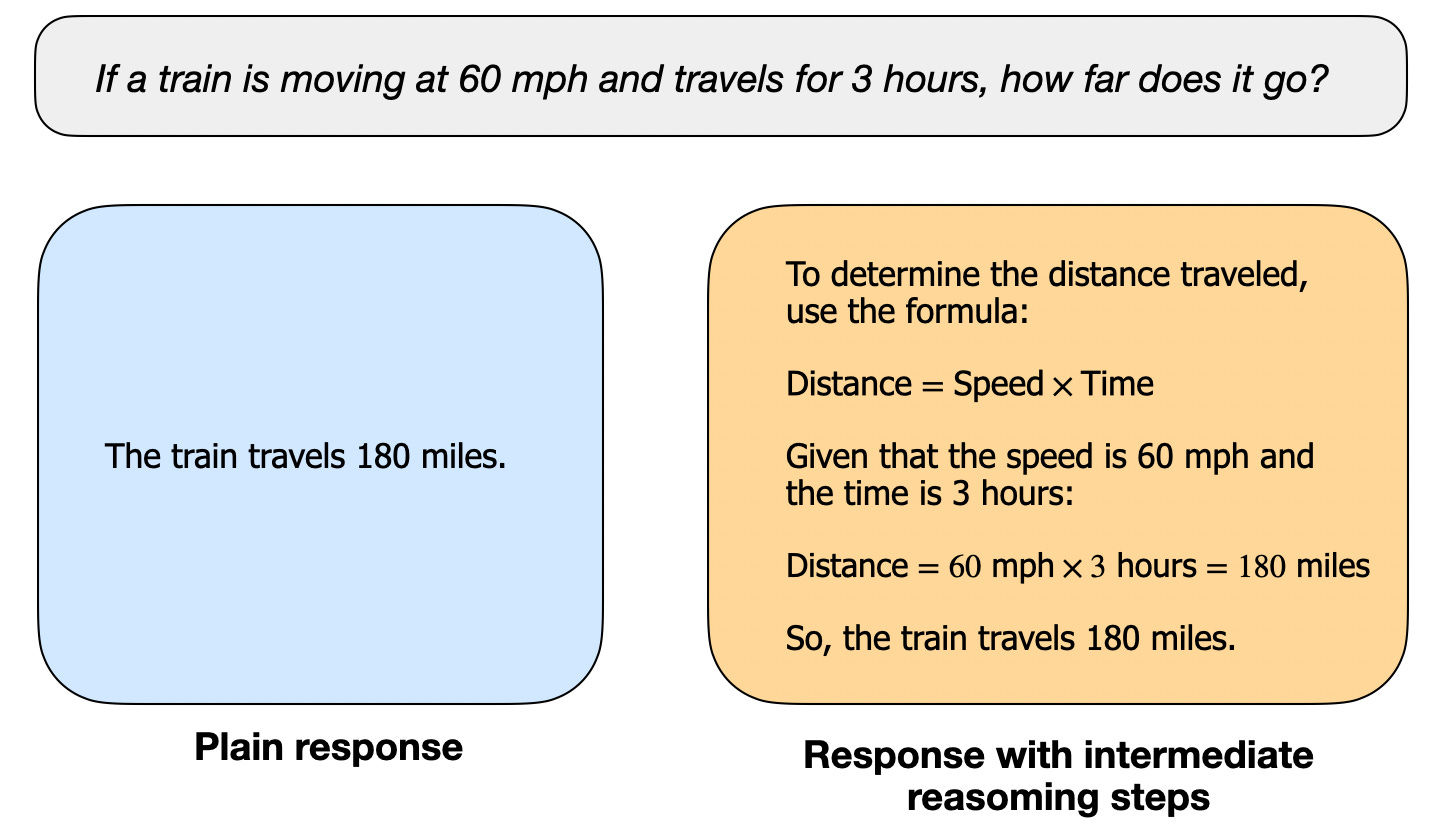
大多数现代LLM具备基本的推理能力,可以回答诸如“如果一列火车以60英里每小时的速度行驶3小时,它会走多远?”这样的问题。因此,今天,当我们提到推理模型时,我们通常指的是在更复杂的推理任务中表现出色的LLM,例如解决谜题、谜语和数学证明。
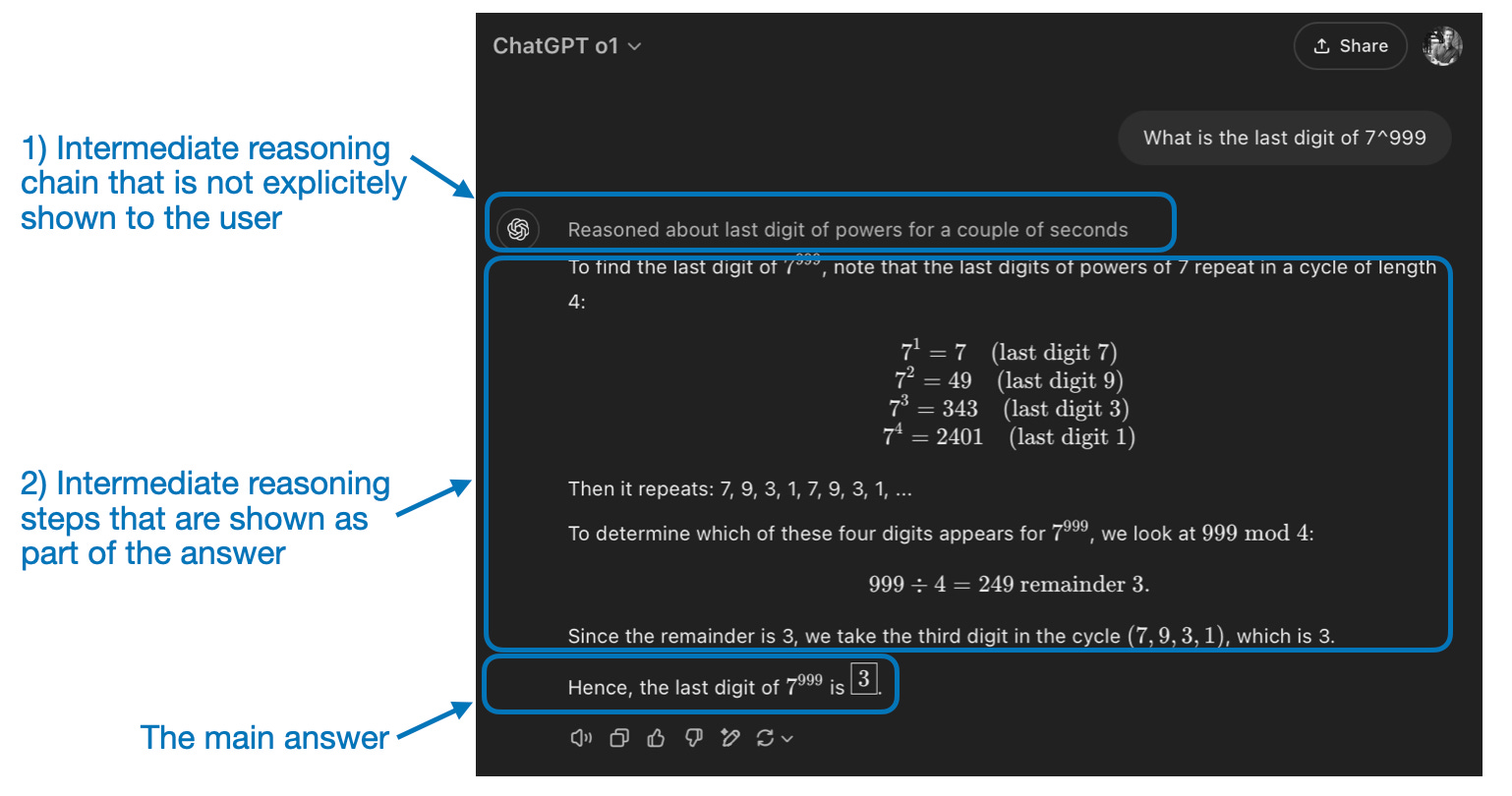
此外,今天大多数被标记为推理模型的LLM在其响应中都包含“思考”或“思维”过程。LLM是否以及如何真正“思考”是一个单独的讨论。
推理模型中的中间步骤可以通过两种方式出现。首先,它们可能会在响应中明确包含,如前图所示。其次,一些推理LLM,如OpenAI的o1,运行多次迭代,其中的中间步骤不会显示给用户。
我们什么时候应该使用推理模型?
现在我们已经定义了推理模型,可以进入更有趣的部分:如何构建和改进用于推理任务的大型语言模型(LLM)。然而,在深入技术细节之前,考虑何时真正需要推理模型是很重要的。
我们什么时候需要推理模型? 推理模型擅长于解决复杂任务,例如解谜、高级数学问题和具有挑战性的编程任务。然而,对于像摘要、翻译或基于知识的问题回答等简单任务,它们并不是必需的。事实上,将推理模型用于所有任务可能既低效又昂贵。例如,推理模型通常使用成本更高、更冗长,有时由于“过度思考”而更容易出错。同样,这里也适用一个简单的规则:为任务使用合适的工具(或类型的LLM)。
推理模型的主要优势和局限性总结在下图中。

简要了解 DeepSeek 训练流程
在下一节讨论构建和改进推理模型的四种主要方法之前,我想简要介绍一下 DeepSeek R1 流程,如 DeepSeek R1 技术报告 中所述。该报告既是一个有趣的案例研究,也是开发推理LLM的蓝图。
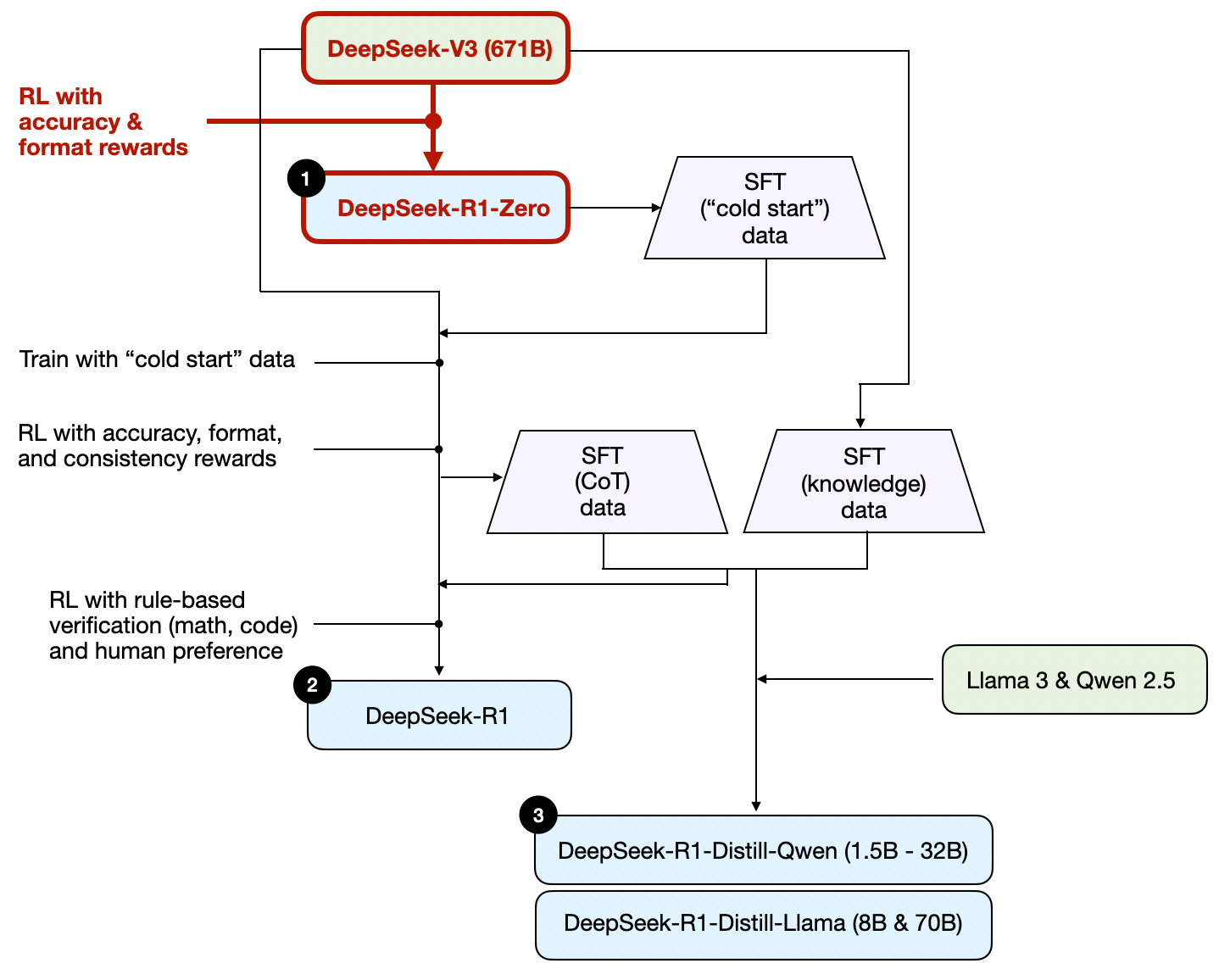
请注意,DeepSeek 并未发布单一的 R1 推理模型,而是推出了三个不同的变体:DeepSeek-R1-Zero、DeepSeek-R1 和 DeepSeek-R1-Distill。
根据技术报告中的描述,我在下图中总结了这些模型的开发过程。
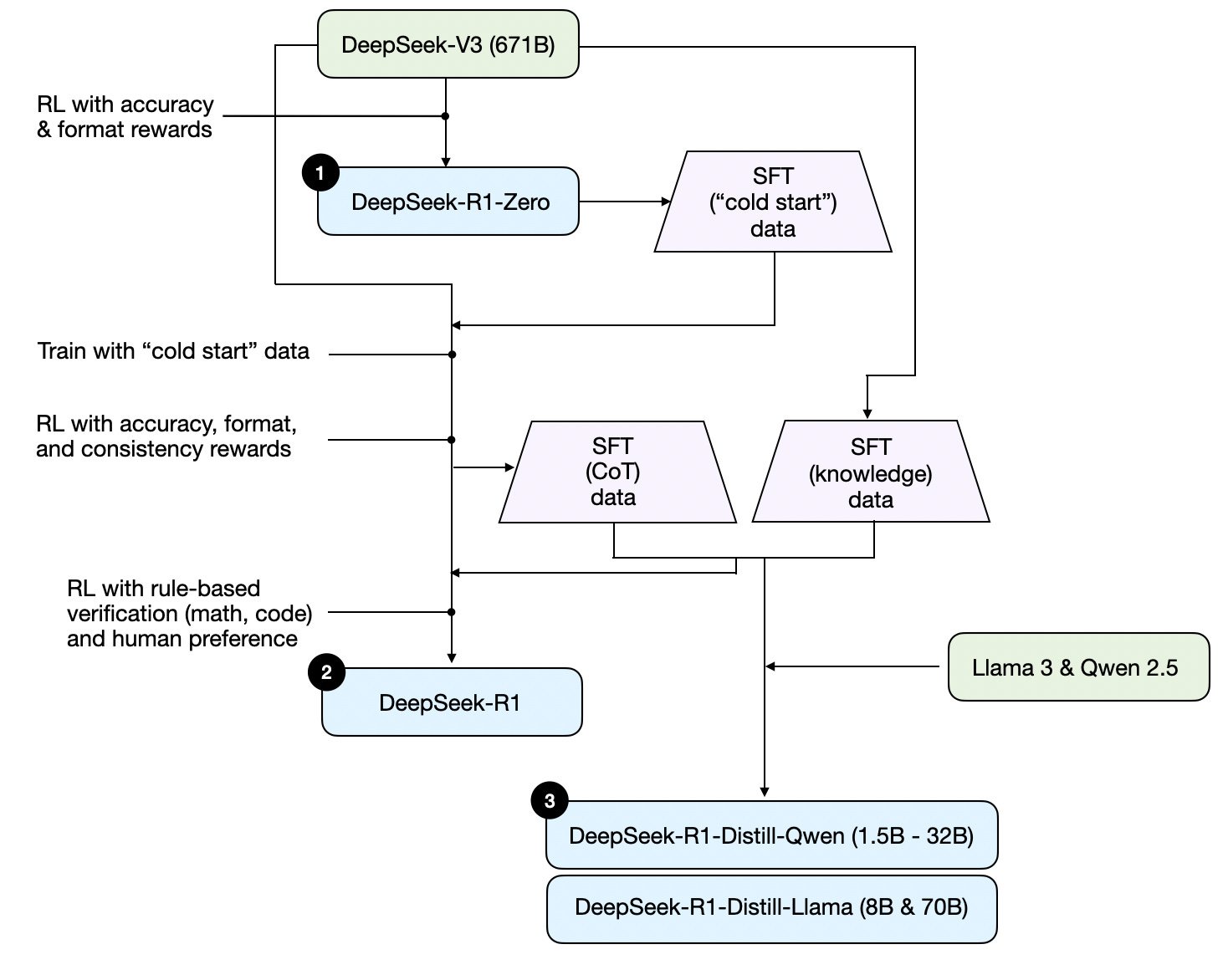
接下来,我们简要介绍上图所示的过程。更多细节将在下一节中讨论,我们将介绍构建和改进推理模型的四种主要方法。
(1) DeepSeek-R1-Zero: 该模型基于2024年12月发布的671B预训练DeepSeek-V3基础模型。研究团队使用两种奖励类型的强化学习(RL)对其进行训练。这种方法被称为“冷启动”训练,因为它没有包括通常是人类反馈强化学习(RLHF)一部分的监督微调(SFT)步骤。
(2) DeepSeek-R1: 这是DeepSeek的旗舰推理模型,基于DeepSeek-R1-Zero构建。团队通过额外的SFT阶段和进一步的RL训练对其进行了进一步的改进,提升了“冷启动”R1-Zero模型。
(3) DeepSeek-R1-Distill*: 利用前面步骤中生成的SFT数据,DeepSeek团队对Qwen和Llama模型进行了微调,以增强其推理能力。虽然这不是传统意义上的蒸馏过程,但该过程涉及在较大的DeepSeek-R1 671B模型的输出上训练较小的模型(Llama 8B和70B,以及Qwen 1.5B–30B)。
构建和改进推理模型的四种主要方法
在本节中,我将概述当前用于增强LLM推理能力的关键技术,以及构建专门推理模型如DeepSeek-R1、OpenAI的o1 & o3等的方法。
注意:o1和o3的具体工作原理在OpenAI之外仍然未知。然而,据传它们利用了一种结合推理和训练技术的方法。
1) 推理时扩展
提高LLM推理能力(或任何能力)的一个方法是推理时扩展。这个术语可以有多种含义,但在此上下文中,它指的是在推理过程中增加计算资源以提高输出质量。
一个粗略的类比是人类在有更多时间思考复杂问题时往往会产生更好的反应。类似地,我们可以应用一些技术,鼓励LLM在生成答案时“多思考”。(尽管,LLM是否真的“思考”是另一个讨论话题。)
推理时扩展的一个简单方法是巧妙的提示工程。一个经典的例子是 链式思维(CoT)提示 ,在输入提示中包含“逐步思考”这样的短语。这鼓励模型生成中间推理步骤,而不是直接跳到最终答案,这通常(但不总是)能在更复杂的问题上产生更准确的结果。(注意,对于简单的知识性问题,如“法国的首都是哪里”,采用这种策略没有意义,这也是判断推理模型是否适合给定输入查询的一个好经验法则。)

上述CoT方法可以被视为推理时扩展,因为它通过生成更多的输出标记使推理变得更昂贵。
另一种推理时刻的扩展方法是使用投票和搜索策略。一个简单的例子是多数投票法,我们让大型语言模型(LLM)生成多个答案,然后通过多数投票选择正确答案。同样,我们可以使用束搜索和其他搜索算法来生成更好的响应。
我强烈推荐我在之前的2024年值得关注的AI研究论文(第二部分)文章中描述的 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters 论文(https://magazine.sebastianraschka.com/p/ai-research-papers-2024-part-2),以获取有关这些不同策略的更多详细信息。
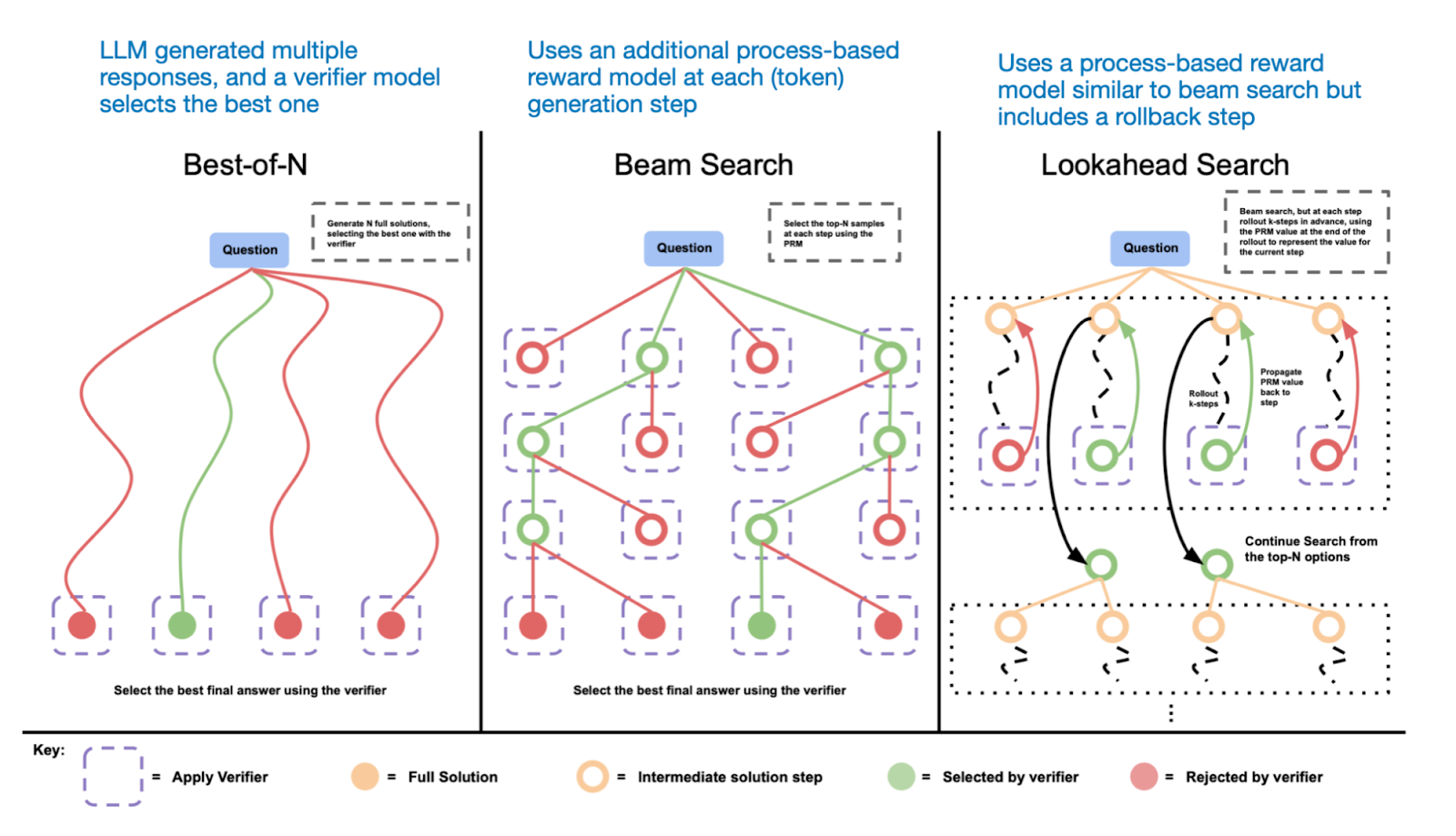
DeepSeek R1技术报告指出其模型不使用推理时刻的扩展。然而,这种技术通常在LLM之上的应用层实现,因此DeepSeek可能在其应用中应用了这一技术。
我怀疑OpenAI的o1和o3模型使用了推理时刻的扩展,这可以解释为什么它们相对昂贵于像GPT-4o这样的模型。除了推理时刻的扩展,o1和o3可能还使用了类似于DeepSeek R1的RL管道进行训练。关于强化学习的更多内容将在下面的两个部分中介绍。
2) 纯强化学习(RL)
我个人从 DeepSeek R1论文 中最感兴趣的一点是他们发现推理作为一种行为从纯强化学习(RL)中出现。让我们更详细地探讨这意味着什么。
如前所述,DeepSeek开发了三种类型的R1模型。第一个, DeepSeek-R1-Zero ,是基于DeepSeek-V3基础模型构建的,这是他们在2024年12月发布的标准预训练LLM。与典型的RL管道不同,通常在RL之前应用监督微调(SFT),DeepSeek-R1-Zero是 仅 通过强化学习训练的,没有初始的SFT阶段,如下图所示。
尽管如此,这一RL过程与通常用于偏好调整LLM的RLHF方法相似。(我在我的文章 LLM Training: RLHF and Its Alternatives 中更详细地介绍了RLHF。)然而,如上所述, DeepSeek-R1-Zero 的关键区别在于他们跳过了用于指令微调的监督微调(SFT)阶段。这就是为什么他们称之为“纯”RL。(虽然,在LLM背景下的RL与传统RL有很大不同,这个话题留待以后讨论。)
对于奖励,他们没有使用基于人类偏好的奖励模型,而是采用了两种类型的奖励:准确性奖励和格式奖励。
-
准确性奖励 使用 LeetCode 编译器来验证编码答案,并使用确定性系统来评估数学回答。
-
格式奖励 依赖于 LLM 评审来确保回答遵循预期格式,例如将推理步骤放在 <think> 标签内。
令人惊讶的是,这种方法足以让 LLM 发展出基本的推理能力。研究人员观察到一个“啊哈!”时刻,模型开始在其回答中生成推理轨迹,尽管没有被明确训练这样做,如下图所示。

虽然 R1-Zero 不是顶级的推理模型,但它通过生成中间“思考”步骤展示了推理能力,如上图所示。这证实了使用纯 RL 开发推理模型是可能的,而 DeepSeek 团队是第一个展示(或至少发表)这种方法的团队。
Ahead of AI 是一个读者支持的出版物。为了接收新文章并支持我的工作,请考虑成为免费或付费订阅者。
3) 监督微调和强化学习(SFT + RL)
接下来,让我们看看 DeepSeek-R1 的开发,DeepSeek 的旗舰推理模型,它作为构建推理模型的蓝图。该模型通过结合额外的监督微调(SFT)和强化学习(RL)来提高其推理性能,从而改进了 DeepSeek-R1-Zero。
请注意,在 RL 之前包含 SFT 阶段实际上是很常见的,如标准的 RLHF 流水线所示。OpenAI 的 o1 可能是使用类似的方法开发的。

如上图所示,DeepSeek 团队使用 DeepSeek-R1-Zero 生成他们称之为“冷启动”的 SFT 数据。“冷启动”一词指的是这些数据是由 DeepSeek-R1-Zero 生成的,而 DeepSeek-R1-Zero 本身并没有经过任何监督微调(SFT)数据的训练。
使用这些冷启动 SFT 数据,DeepSeek 然后通过指令微调训练模型,接着是另一个强化学习(RL)阶段。这个 RL 阶段保留了 DeepSeek-R1-Zero 的 RL 过程中使用的相同准确性和格式奖励。然而,他们增加了一致性奖励以防止语言混合,即模型在一个回答中切换多种语言的情况。
RL 阶段之后是另一轮 SFT 数据收集。在此阶段,使用最新的模型检查点生成了 60 万个链式思维(CoT)SFT 示例,同时使用 DeepSeek-V3 基础模型创建了额外的 20 万个基于知识的 SFT 示例。
这些 60 万 + 20 万个 SFT 样本随后用于另一轮 RL。在此阶段,他们再次使用基于规则的方法为数学和编码问题提供准确性奖励,而其他问题类型则使用人类偏好标签。
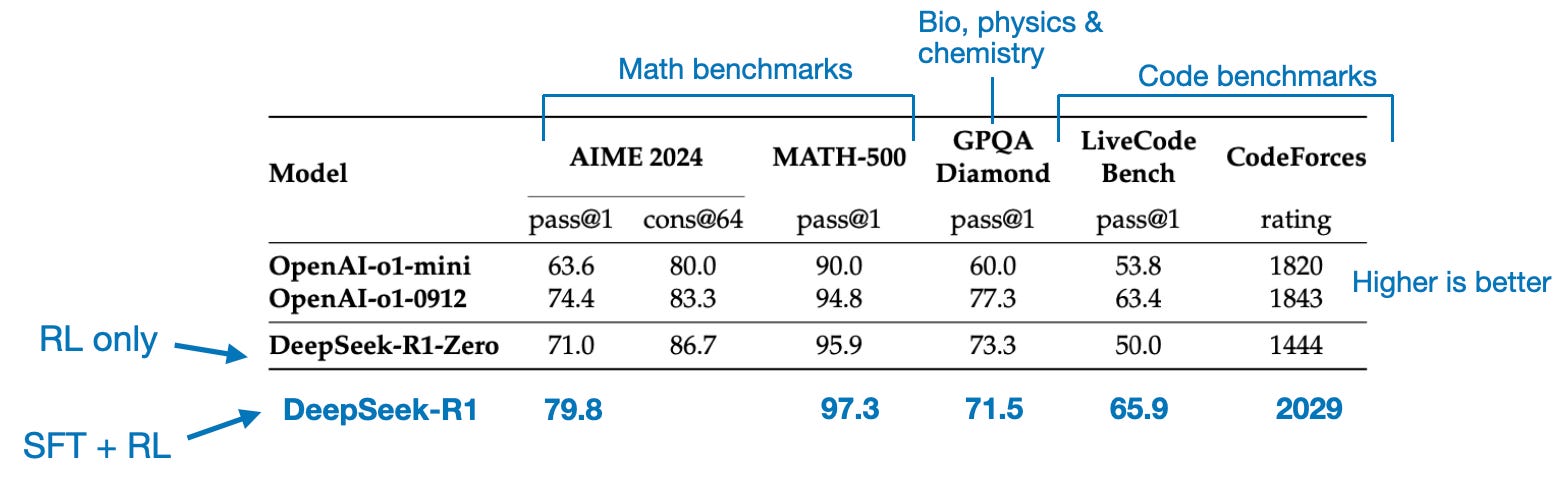
最终模型 DeepSeek-R1 相较于 DeepSeek-R1-Zero 有明显的性能提升,这要归功于额外的 SFT 和 RL 阶段,如下表所示。
4) 纯监督微调 (SFT) 和蒸馏
到目前为止,我们已经介绍了三种构建和改进推理模型的关键方法:
1. 推理时扩展,这是一种无需训练或修改底层模型即可提高推理能力的技术。
2. 纯强化学习 (RL),如在 DeepSeek-R1-Zero 中展示的那样,表明推理可以作为一种学习行为出现,而无需监督微调。
3. 监督微调 (SFT) 加上 RL,这导致了 DeepSeek-R1 的出现,DeepSeek 的旗舰推理模型。
那么,还剩下什么呢?模型“蒸馏”。
令人惊讶的是,DeepSeek 还发布了通过他们称之为 蒸馏 的过程训练的小型模型。然而,在 LLMs 的背景下,蒸馏不一定遵循深度学习中使用的经典知识蒸馏方法。传统上,在知识蒸馏中(如我在 《机器学习问答与人工智能》 一书第六章中简要描述的),一个较小的学生模型在较大教师模型的 logits 和目标数据集上进行训练。
相反,这里的蒸馏是指对较小的 LLMs 进行指令微调,例如 Llama 8B 和 70B 以及 Qwen 2.5 模型(0.5B 到 32B),在由较大 LLMs 生成的 SFT 数据集上进行训练。具体来说,这些较大的 LLMs 是 DeepSeek-V3 和 DeepSeek-R1 的一个中间检查点。事实上,用于此蒸馏过程的 SFT 数据与用于训练 DeepSeek-R1 的数据集相同,如前一节所述。
为了澄清这个过程,我在下面的图表中突出显示了蒸馏部分。
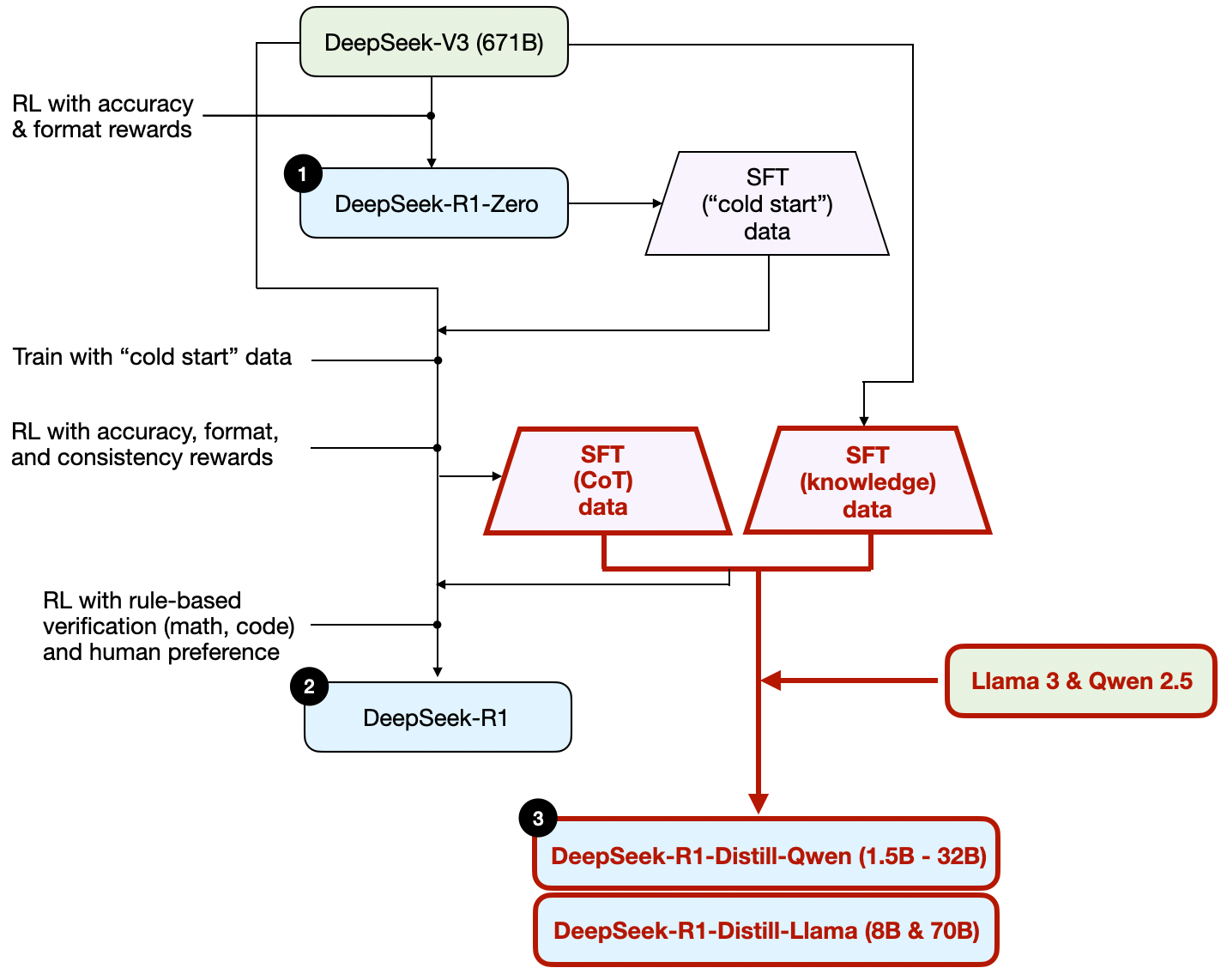
他们为什么要开发这些蒸馏模型?在我看来,有两个关键原因:
1. 较小的模型更高效。这意味着它们运行成本更低,而且可以在低端硬件上运行,这对许多研究人员和爱好者来说尤其有趣。
2. 纯 SFT 的案例研究。这些蒸馏模型作为一个有趣的基准,展示了纯监督微调 (SFT) 在没有强化学习的情况下可以将模型带到多远。
下表比较了这些蒸馏模型与其他流行模型以及 DeepSeek-R1-Zero 和 DeepSeek-R1 的性能。
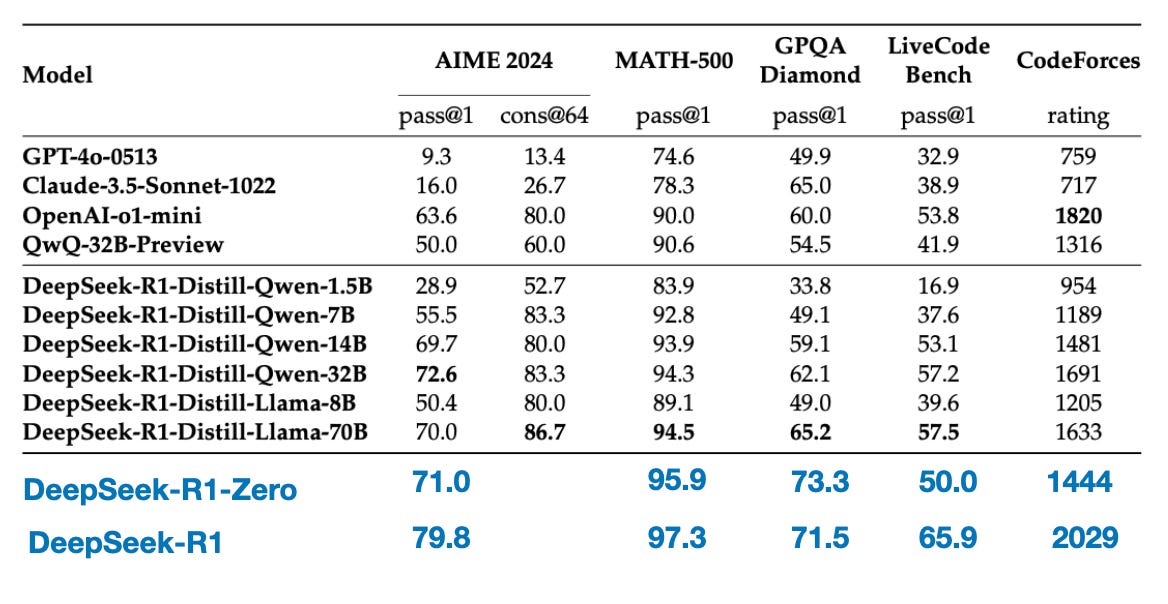
正如我们所见,蒸馏模型明显比 DeepSeek-R1 弱,但相对于 DeepSeek-R1-Zero 来说,它们的表现却出乎意料地强,尽管它们的规模小了好几个数量级。值得注意的是,这些模型与 o1 mini 的表现相比也相当不错(我怀疑 o1-mini 本身可能是 o1 的一个类似蒸馏版本)。
在结束本节的结论之前,还有一个有趣的比较值得一提。DeepSeek 团队测试了在 DeepSeek-R1-Zero 中观察到的突现推理行为是否也能在较小的模型中出现。为此,他们将 DeepSeek-R1-Zero 的纯 RL 方法直接应用于 Qwen-32B。
这个实验的结果总结在下表中,其中 QwQ-32B-Preview 作为基于 Qwen 2.5 32B 开发的参考推理模型(我认为训练细节从未披露)。这个比较提供了一些额外的见解,说明纯 RL 是否能在比 DeepSeek-R1-Zero 小得多的模型中引发推理能力。
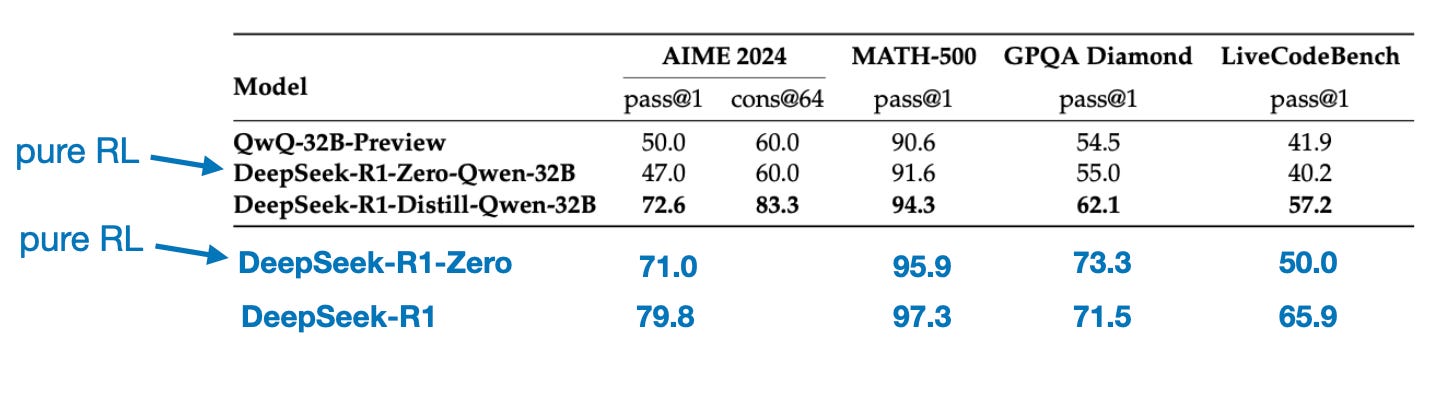
有趣的是,结果表明蒸馏对于较小的模型比纯 RL 更有效。这与 RL 单独可能不足以在这种规模的模型中引发强推理能力的观点一致,而在高质量推理数据上的 SFT 则可能是处理小模型时更有效的策略。
为了完整性,表中还可以看到更多的比较:
1. 使用 SFT + RL 训练的 Qwen-32B,类似于 DeepSeek-R1 的开发方式。这将有助于确定在 RL 和 SFT 结合时,与纯 RL 和纯 SFT 相比,可以取得多少改进。
2. 使用纯 SFT 训练的 DeepSeek-V3,类似于蒸馏模型的创建方式。这将允许直接比较 RL + SFT 相对于纯 SFT 的效果。
Ahead of AI 是一个由读者支持的出版物。要接收新文章并支持我的工作,请考虑成为免费或付费订阅者。
结论
在本节中,我们探讨了构建和改进推理模型的四种不同策略:
1. 推理时扩展不需要额外的训练,但会增加推理成本,使得随着用户数量或查询量的增长,大规模部署变得更昂贵。然而,对于已经很强的模型来说,这仍然是一个不费脑筋的改进方法。我强烈怀疑 o1 利用了推理时扩展,这有助于解释为什么它在每个 token 的基础上比 DeepSeek-R1 更昂贵。
2. 纯 RL 对于研究目的很有趣,因为它提供了关于推理作为一种突现行为的见解。然而,在实际模型开发中,RL + SFT 是首选方法,因为它能产生更强的推理模型。我强烈怀疑 o1 也是使用 RL + SFT 训练的。更确切地说,我相信 o1 从一个比 DeepSeek-R1 更弱、更小的基础模型开始,但通过 RL + SFT 和推理时扩展来弥补。
3. 如上所述,RL + SFT 是构建高性能推理模型的关键方法。DeepSeek-R1 是一个展示如何做到这一点的好蓝图。
4. 蒸馏是一种有吸引力的方法,特别是用于创建更小、更高效的模型。然而,限制在于蒸馏并不能推动创新或产生下一代推理模型。例如,蒸馏总是依赖于现有的、更强的模型来生成监督微调 (SFT) 数据。
我期待看到的一个有趣方面是将RL + SFT(方法3)与推理时缩放(方法1)结合起来。这可能就是OpenAI的o1正在做的事情,只不过它可能基于一个比DeepSeek-R1更弱的基础模型,这解释了为什么DeepSeek-R1在推理时表现如此出色,同时保持相对便宜的成本。
关于DeepSeek R1的思考
最近几周,很多人询问我对DeepSeek-R1模型的看法。简而言之,我认为它们是一个了不起的成就。作为一名研究工程师,我特别欣赏详细的技术报告,它提供了我可以学习的方法论见解。
其中一个最吸引人的收获是推理如何从纯RL中作为一种行为出现。而且令人印象深刻的是,DeepSeek在MIT许可下开源了他们的模型,这比Meta的Llama模型的限制更少。
它与o1相比如何?
DeepSeek-R1比o1更好吗?我会说它们大致在同一水平。然而,值得注意的是,DeepSeek-R1在推理时更高效。这表明DeepSeek可能在训练过程中投入了更多,而OpenAI可能更多地依赖于o1的推理时缩放。
话虽如此,很难直接比较o1和DeepSeek-R1,因为OpenAI没有披露太多关于o1的信息。例如,我们不知道:
-
o1也是专家混合(MoE)吗?
-
o1有多大?
-
o1可能只是GPT-4o的一个稍微改进的版本,只有最小的RL + SFT和广泛的推理时缩放吗?
在不知道这些细节的情况下,直接比较仍然是苹果和橙子的比较。
训练DeepSeek-R1的成本
另一个讨论点是开发DeepSeek-R1的成本。有人提到大约600万美元的训练成本,但他们可能混淆了去年12月发布的基础模型DeepSeek-V3和DeepSeek-R1。
600万美元的估计是基于每GPU小时2美元的假设和DeepSeek-V3最终训练运行所需的GPU小时数,这最初是在2024年12月讨论的。
然而,DeepSeek团队从未披露R1的确切GPU小时数或开发成本,因此任何成本估计都纯属猜测。
<
上面提到的两个项目表明,即使在预算有限的情况下,推理模型的研究也能取得有趣的成果。虽然这两种方法都复刻了 DeepSeek-R1 的方法,一个专注于纯强化学习(TinyZero),另一个专注于纯监督微调(Sky-T1),但探索如何进一步扩展这些想法将会很有趣。
超越传统的监督微调:旅程学习
去年我遇到的一个特别有趣的方法在论文 O1 Replication Journey: A Strategic Progress Report – Part 1 中有所描述。尽管标题如此,论文实际上并没有复刻 o1。相反,它介绍了一种改进蒸馏(纯监督微调)过程的不同方法。
论文中的关键思想是“旅程学习”作为“捷径学习”的替代方案。
-
捷径学习指的是传统的指令微调方法,其中模型仅通过正确的解决路径进行训练。
-
而旅程学习则包括错误的解决路径,让模型从错误中学习。
这种方法与在 TinyZero 的纯强化学习训练中观察到的自我验证能力有些相关,但它完全通过监督微调来改进模型。通过让模型接触错误的推理路径及其修正,旅程学习也可能增强自我纠正能力,从而可能使推理模型更可靠。
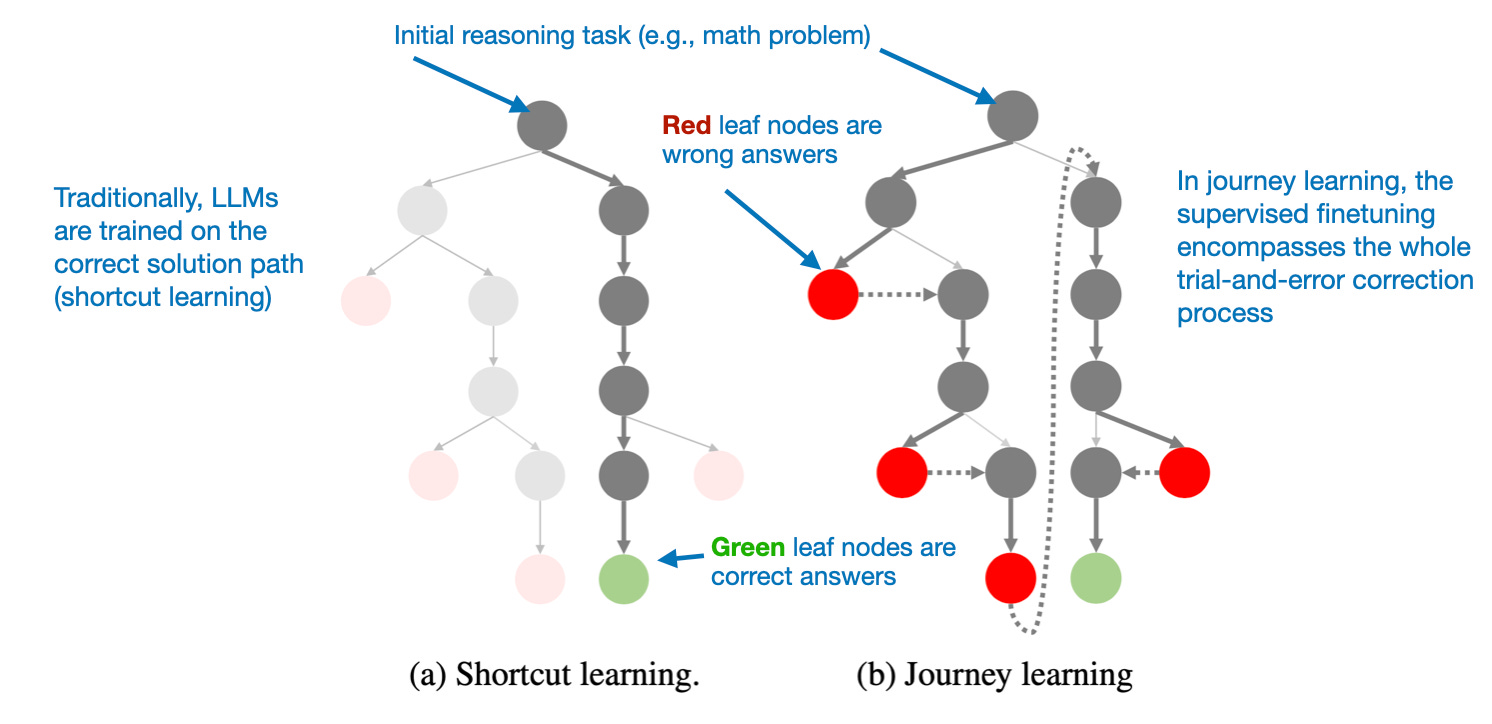
这可能是未来研究的一个令人兴奋的方向,特别是对于低预算的推理模型开发,其中基于强化学习的方法可能在计算上不切实际。
总之,目前在推理模型领域有很多有趣的工作正在进行,我相信在接下来的几个月里我们会看到更多令人兴奋的研究成果!
这本杂志是我的个人热情项目。对于那些希望支持我的人,请考虑购买一本我的 《从零开始构建大型语言模型》书籍 。(我相信你会从这本书中获得很多,因为它以其他地方找不到的详细程度解释了大型语言模型的工作原理。)

如果您读过这本书并有几分钟的时间,我非常感激您能在 亚马逊上留下简短的评论 。这对我们作者帮助很大!
您的支持对我们意义重大!谢谢您!
文章来源:Understanding Reasoning LLMs
关键问题与行动计划
关键问题 1: 如何评估推理模型在特定行业中的应用潜力和市场需求?
行动计划:
- 行业分析:研究团队将针对医疗、金融、教育等关键行业,分析推理模型的潜在应用场景,识别出哪些复杂任务最需要推理能力,并评估市场需求的规模。
- 竞争对手分析:数据团队将收集和分析现有推理模型在这些行业中的应用案例,评估其成功与失败的因素,以便为新投资机会提供参考。
关键问题 2: 推理模型的开发成本与效益如何平衡?
行动计划:
- 成本效益分析:研究团队将对比不同推理模型的开发成本(如DeepSeek-R1与TinyZero)与其市场表现,评估在不同预算下的最佳开发策略。
- 预算优化策略:数据团队将收集关于推理模型开发的公开数据,分析不同开发方法(如纯RL、SFT+RL、蒸馏等)的成本与效益,提出适合初创企业的预算优化建议。
关键问题 3: 如何利用现有的推理模型技术推动新产品的创新?
行动计划:
- 技术趋势研究:研究团队将跟踪推理模型领域的最新技术进展,识别出可以应用于新产品开发的关键技术和方法。
- 产品原型开发:数据团队将与技术团队合作,基于最新的推理模型技术,开发初步的产品原型,并进行市场测试,以验证其商业可行性。
请告诉我们你对此篇总结的改进建议,如存在内容不相关、低质、重复或评分不准确,我们会对其进行分析修正